
OS系统集群方案
不间断的无故障的业务运行环境是每一个企业IT系统部署要求的重中之重。任何一个发生在关键服务上的停顿故障都会导致直接和间接的企业经济损失以及客户的满意度下降。虽然红帽企业版Linux操作系统已经提供高度的容错能力,但是关键业务系统仍旧需要成熟的技术来实现服务的高可用性,尽可能减少和缩短服务停顿的次数和时间。
传统的通过冗余和复制硬件设备的解决方式既昂贵且局限性大,用户只能通过这样的方式解决企业中最关键的业务应用对 于可用性的要求。 因此很多企业内部的重要应用由于缺乏高性价比的方案而失去保护,面临着灾难后的长时间恢复和数据的丢失。 同样的情况下,当企业的IT部门需要对关键应用所处软硬件环境进行调整,或仅仅是作系统维护的时候,这种计划内的停机也会造成应用重新上线前的长时间服务 停止以及潜在的数据丢失。
红帽的企业集群解决方案(RHCS)是全球领先的高可用性解决方案,专为红帽企业Linux量身定做,是全球企业Linux厂商中唯一提供原生集群解决方 案的厂商。RHCS集群经过红帽公司全球研发团队以及广大开发者社区的多年打造,已经成为企业级Linux平台上顶尖的高可用解决方案。
红帽RHCS集群采用了业界成熟的技术和主流国际标准,遵循高度安全和可靠的苛刻要求,被广泛的部署在电信,金融,政府,军队,制造,医疗,商贸,教育等各行业。
通过长年于主流硬件制造商及软件制造商的研发协作与合作,红帽RHCS集群已经在几乎所有主流硬件平台上运行,并且高度支持主流的数据库及中间件应用,针对绝大多数网站/网络所必须的应用服务也提供了完整的支持。 红帽RHCS集群方案已经预置了对主要网络和数据库服务的支持,用户可通过红帽全球专家服务(GlobalProfessional Service)完成对特殊服务和应用的集群定制部署。
Red Hat Cluster Suite即红帽集群套件,它是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。REDHAT公司在2007年发布RHEL5时,就将原本作为独立软件发售的用于构建企业级集群的集群套件RHCS集成到了操作系统中一同发布。
RHCS提供如下两种不同类型的集群:
• 应用/服务故障切换——通过创建N个节点的服务器集群来实现关键应用和服务的故障切换
• IP负载均衡——对一群服务器上收到的IP网络请求进行负载均衡
• 最多支持128个节点(红帽3和4支持16个节点)
• 可同时为多个应用提供高可用性
• NFS/CIFS故障切换:支持UNIX和WINDOWS环境下使用的高可用性文件
• 完全共享的存储子系统:所有集群成员都可以访问同一个存储子系统
• 综合数据完整性:使用最新的I/O屏障(barrier)技术,如可编辑的嵌入式和外部电源开关装置(powerswitches)
• 服务故障切换:它可以确保及时发现硬件停止运行或故障的发生并自动恢复系统,同时,它还可以通过监控应用来确保应用的正确运行并在其发生故障时进行自动重启
RHCS组件说明:
CMAN: Cluster manager是一个分布式集群管理工具,运行在集群的各个节点上,为RHCS提供集群管理任务。它用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的有关系。当集群中某个节点出现故障时,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。CMAN根据每个节点的运行状态,统计出一个法定节点数,作为集群是否存活的依据。当整个集群中有多于一半的节点处于激活状态时,表示达到了法定节点数,此集群可以正常运行,当集群中有一半或少于一半的节点处于激活状态时,表示没有达到法定的节点数,此时整个集群系统将变得不可用。CMAN依赖于CCS,并且CMAN通过CCS读取cluster.conf文件。
rgmanager: Resource Group Manager主要用来监督、启动、停止集群的应用、服务和资源,与cman一样,rgmanager也是RHCS中的一个核心服务,可通过系统中的serivce命令进行启/停操作;当一个节点的服务失败时,rgmanager提供自动透明的Failover错误切换功能:可以将服务从失败节点转移至其它健康节点。RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
DLM: Distributed LockManager是一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制。DLM运行在每个节点上GFS通过锁管理器的机制来同步访问文件系统的元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大提高了处理性能。同时,DLM避免了单个节点失败需要整体恢复的性能瓶颈。另外,DLM的请求是本地的,不需要网络请求,因此请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。
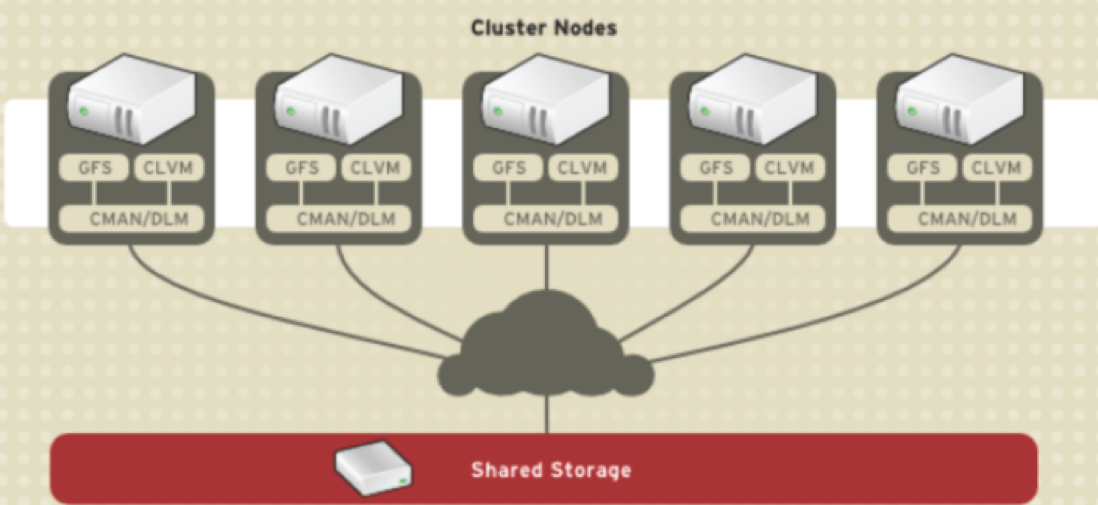
CCS: Cluster Configuration System主要用于集群配置文件管理和配置文件在节点之间的同步。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态。当这个文件发生任何变化时,都将些变化更新至集群中的每个节点上,时刻保持每个节点的配置文件同步;Cluster.conf是一个XML文件,其中包含集群名称,集群节点信息,集群资源和服务信息,fence设备等。
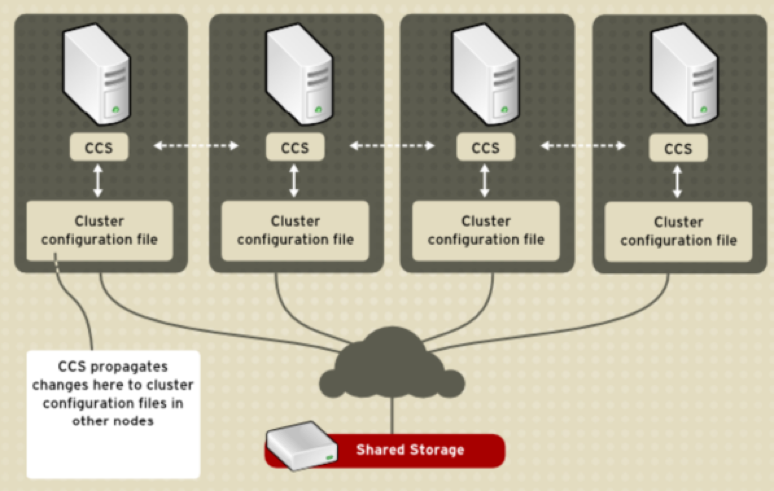
Failover Domain: 与服务相关,Failover Domain指定了集群中某个节点故障以后,该节点上的Service和Resource所能够转移的目标节点,进而限定了一个Resource能够转移的节点范围,可以理解为服务的故障转移域;每个Node都允许与多个Failover Domain进行绑定,也就是说每个Node都可以为多个Service服务,因此可以实现双主方式的集群配置。RHCS中一个服务必须要定义Failover Domain,在定义故障转移域前要定义好故障发生时的优先动作,是先重启服务还是进行转移,在定义故障转移域时可以按照节点在故障转移域中的次序设定转移的优先级,如果没有设置优先,集群高可用服务可在转移域内的任意节点间转移。
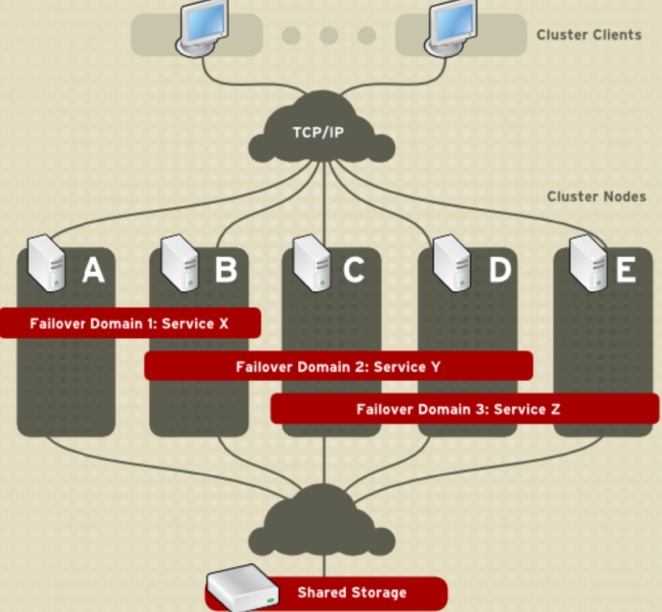
Fence: Fence主要就是通过服务器或存储本身的硬件管理接口,又或者是外部电源管理设备,来对服务器或存储发起直接的硬件管理指令,控制服务器或存储链路的开关。因此,Fence机制也被称为”I/O屏障”技术。当CMAN确定一个节点离线后,它在集群结构中通告这个问题节点,fenced进程将问题节点隔离,彻底断开问题节点的所有I/O连接,防止问题节点破坏共享数据,严格保证集群环境中企业核心数据的完整性。它可以避免因出现不可预知的情况而造成的“脑裂”现象。Split-Brain(脑裂)是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用抢夺。
Fence工作原理: 当意外原因导致主机异常或宕机时,备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
Fence实例: 当节点A上的栅过程发现C节点失效时,它通过栅代理通知光纤通道交换机将C节点隔离,从而释放占用的共享存储。当A上的栅过程发现C节点失效时,它通过栅代理直接对服务器做电源poweron/off,而不是去执行操作系统的开关机指令。
RHCS的Fence设备分为内部和外部两种Fence。内部fence有IBMRSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SANswitch ,Networkswitch等。
集群配置和管理工具: RHCS提供了多种集群配置和管理工具,常用有基于GUI的system-config-cluster,conga等,还提供了基于命令行的管理工具。System-config-cluster由集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态,一般用于早期的RHCS版本中。Conga是新的基于网络的集群配置工具。它是web界面管理的,由luci和ricci组成,luci可以安装在一台独立的计算机上,也可安装在节点上,用于配置和管理集群,ricci是一个代理,安装在每个集群节点上,luci通过ricci和集群中的每个节点通信。
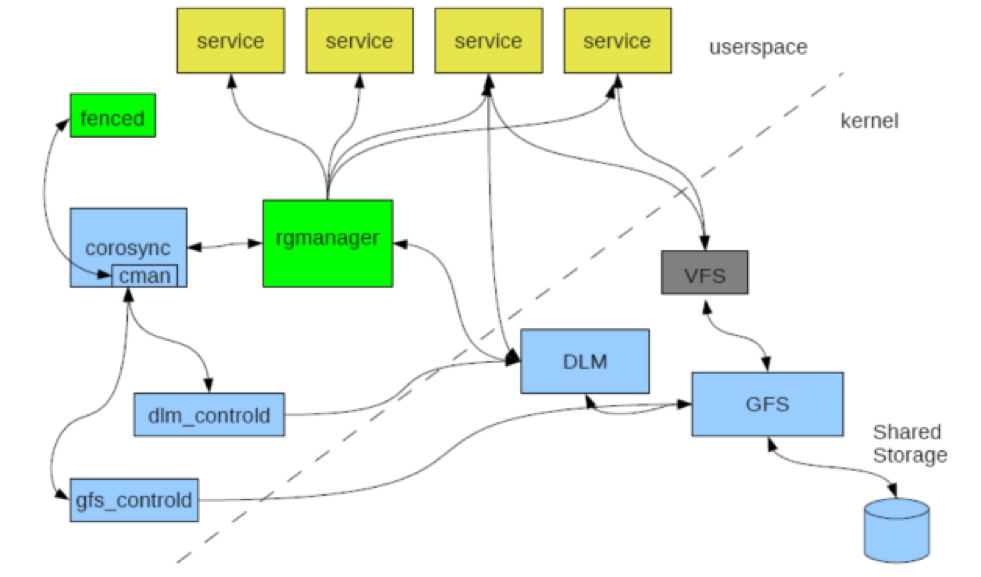
在RHEL4中cman是一个基于内核的对称通用集群管理器,在RHEL5以后cman基于openAIS工作,大多数功能都转移到用户空间,只有GFS,DLM和lock_dlm工作在内核模块;aisexec是openAIS的核心进程,完成基本心跳信息传递,成员关系管理等,cman作为aisexec的一个插件提供投票功能,cman通过rgmanager来管理资源,rgmanager的守护进程为groupd;dlm_controld分布式锁控制器,完成锁管理,即施加锁和释放锁等等,lock_dlmd是锁管理器,一个应用程序想要持有锁需要通过libdlm库,借助DLM机制通过lock_dlm对文件施加锁,lock_dlm与其他节点完成锁通知。
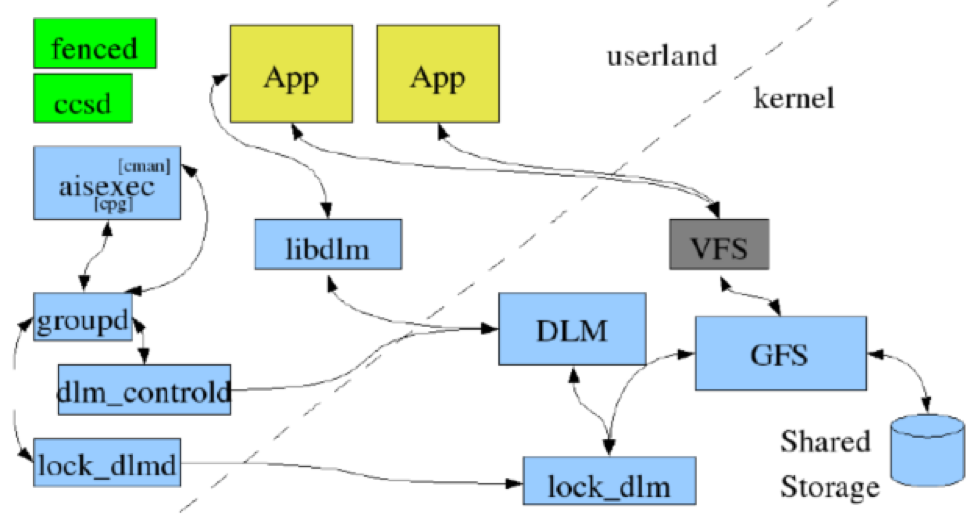
RHCS in RHEL6:
在RHEL6上RHCS定义高可用资源架构的更加明晰,完全借助于类似corosync的机制,cman不再借助于openAIS,而是借助于corosync;资源管理完全借助于rgmanager,在rgmanager内部就可以完成资源配置同步传递,取消了ccsd,将资源管理的配置与基础信息架构层的配置分开,将lock_dlmd整合进dlm_controld中统一实现;对GFS文件系统管理使用gfs_controld这个独立组件完成,gfs_controld是RHCS专门为管理GFS文件系统提供的一个优化控制进程,而对OCFS的管理使用dlm_controld,如果用不到集群文件系统,可以不启动这个两个组件,只需要cman和rgmanage即可。
传统的通过冗余和复制硬件设备的解决方式既昂贵且局限性大,用户只能通过这样的方式解决企业中最关键的业务应用对 于可用性的要求。 因此很多企业内部的重要应用由于缺乏高性价比的方案而失去保护,面临着灾难后的长时间恢复和数据的丢失。 同样的情况下,当企业的IT部门需要对关键应用所处软硬件环境进行调整,或仅仅是作系统维护的时候,这种计划内的停机也会造成应用重新上线前的长时间服务 停止以及潜在的数据丢失。
红帽的企业集群解决方案(RHCS)是全球领先的高可用性解决方案,专为红帽企业Linux量身定做,是全球企业Linux厂商中唯一提供原生集群解决方 案的厂商。RHCS集群经过红帽公司全球研发团队以及广大开发者社区的多年打造,已经成为企业级Linux平台上顶尖的高可用解决方案。
红帽RHCS集群采用了业界成熟的技术和主流国际标准,遵循高度安全和可靠的苛刻要求,被广泛的部署在电信,金融,政府,军队,制造,医疗,商贸,教育等各行业。
通过长年于主流硬件制造商及软件制造商的研发协作与合作,红帽RHCS集群已经在几乎所有主流硬件平台上运行,并且高度支持主流的数据库及中间件应用,针对绝大多数网站/网络所必须的应用服务也提供了完整的支持。 红帽RHCS集群方案已经预置了对主要网络和数据库服务的支持,用户可通过红帽全球专家服务(GlobalProfessional Service)完成对特殊服务和应用的集群定制部署。
RHCS:
Red Hat Cluster Suite即红帽集群套件,它是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。REDHAT公司在2007年发布RHEL5时,就将原本作为独立软件发售的用于构建企业级集群的集群套件RHCS集成到了操作系统中一同发布。
RHCS提供如下两种不同类型的集群:
• 应用/服务故障切换——通过创建N个节点的服务器集群来实现关键应用和服务的故障切换
• IP负载均衡——对一群服务器上收到的IP网络请求进行负载均衡
RHCS技术要点:
• 最多支持128个节点(红帽3和4支持16个节点)
• 可同时为多个应用提供高可用性
• NFS/CIFS故障切换:支持UNIX和WINDOWS环境下使用的高可用性文件
• 完全共享的存储子系统:所有集群成员都可以访问同一个存储子系统
• 综合数据完整性:使用最新的I/O屏障(barrier)技术,如可编辑的嵌入式和外部电源开关装置(powerswitches)
• 服务故障切换:它可以确保及时发现硬件停止运行或故障的发生并自动恢复系统,同时,它还可以通过监控应用来确保应用的正确运行并在其发生故障时进行自动重启
RHCS组件说明:
CMAN: Cluster manager是一个分布式集群管理工具,运行在集群的各个节点上,为RHCS提供集群管理任务。它用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的有关系。当集群中某个节点出现故障时,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。CMAN根据每个节点的运行状态,统计出一个法定节点数,作为集群是否存活的依据。当整个集群中有多于一半的节点处于激活状态时,表示达到了法定节点数,此集群可以正常运行,当集群中有一半或少于一半的节点处于激活状态时,表示没有达到法定的节点数,此时整个集群系统将变得不可用。CMAN依赖于CCS,并且CMAN通过CCS读取cluster.conf文件。
rgmanager: Resource Group Manager主要用来监督、启动、停止集群的应用、服务和资源,与cman一样,rgmanager也是RHCS中的一个核心服务,可通过系统中的serivce命令进行启/停操作;当一个节点的服务失败时,rgmanager提供自动透明的Failover错误切换功能:可以将服务从失败节点转移至其它健康节点。RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
DLM: Distributed LockManager是一个分布式锁管理器,它是RHCS的一个底层基础构件,同时也为集群提供了一个公用的锁运行机制。DLM运行在每个节点上GFS通过锁管理器的机制来同步访问文件系统的元数据。CLVM通过锁管理器来同步更新数据到LVM卷和卷组。DLM不需要设定锁管理服务器,它采用对等的锁管理方式,大大提高了处理性能。同时,DLM避免了单个节点失败需要整体恢复的性能瓶颈。另外,DLM的请求是本地的,不需要网络请求,因此请求会立即生效。最后,DLM通过分层机制,可以实现多个锁空间的并行锁模式。
CCS: Cluster Configuration System主要用于集群配置文件管理和配置文件在节点之间的同步。CCS运行在集群的每个节点上,监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态。当这个文件发生任何变化时,都将些变化更新至集群中的每个节点上,时刻保持每个节点的配置文件同步;Cluster.conf是一个XML文件,其中包含集群名称,集群节点信息,集群资源和服务信息,fence设备等。
Failover Domain: 与服务相关,Failover Domain指定了集群中某个节点故障以后,该节点上的Service和Resource所能够转移的目标节点,进而限定了一个Resource能够转移的节点范围,可以理解为服务的故障转移域;每个Node都允许与多个Failover Domain进行绑定,也就是说每个Node都可以为多个Service服务,因此可以实现双主方式的集群配置。RHCS中一个服务必须要定义Failover Domain,在定义故障转移域前要定义好故障发生时的优先动作,是先重启服务还是进行转移,在定义故障转移域时可以按照节点在故障转移域中的次序设定转移的优先级,如果没有设置优先,集群高可用服务可在转移域内的任意节点间转移。
Fence: Fence主要就是通过服务器或存储本身的硬件管理接口,又或者是外部电源管理设备,来对服务器或存储发起直接的硬件管理指令,控制服务器或存储链路的开关。因此,Fence机制也被称为”I/O屏障”技术。当CMAN确定一个节点离线后,它在集群结构中通告这个问题节点,fenced进程将问题节点隔离,彻底断开问题节点的所有I/O连接,防止问题节点破坏共享数据,严格保证集群环境中企业核心数据的完整性。它可以避免因出现不可预知的情况而造成的“脑裂”现象。Split-Brain(脑裂)是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用抢夺。
Fence工作原理: 当意外原因导致主机异常或宕机时,备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
Fence实例: 当节点A上的栅过程发现C节点失效时,它通过栅代理通知光纤通道交换机将C节点隔离,从而释放占用的共享存储。当A上的栅过程发现C节点失效时,它通过栅代理直接对服务器做电源poweron/off,而不是去执行操作系统的开关机指令。
RHCS的Fence设备分为内部和外部两种Fence。内部fence有IBMRSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SANswitch ,Networkswitch等。
集群配置和管理工具: RHCS提供了多种集群配置和管理工具,常用有基于GUI的system-config-cluster,conga等,还提供了基于命令行的管理工具。System-config-cluster由集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态,一般用于早期的RHCS版本中。Conga是新的基于网络的集群配置工具。它是web界面管理的,由luci和ricci组成,luci可以安装在一台独立的计算机上,也可安装在节点上,用于配置和管理集群,ricci是一个代理,安装在每个集群节点上,luci通过ricci和集群中的每个节点通信。
RHCS in RHEL5:
在RHEL4中cman是一个基于内核的对称通用集群管理器,在RHEL5以后cman基于openAIS工作,大多数功能都转移到用户空间,只有GFS,DLM和lock_dlm工作在内核模块;aisexec是openAIS的核心进程,完成基本心跳信息传递,成员关系管理等,cman作为aisexec的一个插件提供投票功能,cman通过rgmanager来管理资源,rgmanager的守护进程为groupd;dlm_controld分布式锁控制器,完成锁管理,即施加锁和释放锁等等,lock_dlmd是锁管理器,一个应用程序想要持有锁需要通过libdlm库,借助DLM机制通过lock_dlm对文件施加锁,lock_dlm与其他节点完成锁通知。
RHCS in RHEL6:
在RHEL6上RHCS定义高可用资源架构的更加明晰,完全借助于类似corosync的机制,cman不再借助于openAIS,而是借助于corosync;资源管理完全借助于rgmanager,在rgmanager内部就可以完成资源配置同步传递,取消了ccsd,将资源管理的配置与基础信息架构层的配置分开,将lock_dlmd整合进dlm_controld中统一实现;对GFS文件系统管理使用gfs_controld这个独立组件完成,gfs_controld是RHCS专门为管理GFS文件系统提供的一个优化控制进程,而对OCFS的管理使用dlm_controld,如果用不到集群文件系统,可以不启动这个两个组件,只需要cman和rgmanage即可。